Encoding
Compression
In real life, files are transferred from one place to another, over the internet, millions of times. As with solid files like wads of paper, it would make it a lot easier and efficient to transfer if they were smaller and more compact… the same applies here. With millions of files being uploaded and transferred across the internet every day, files are required to be compressed so that space is not wasted on the world-wide web. This is why compression exists. Compression reduces the amount of space required to store files on a hard drive or server and makes them quicker to send. There are many different examples of compression in the modern world such as JPEG (image), MP3 (for music), MPEG (movies or any combination of audio and pictures), and ZIP (used for many things).
Run-Length-Encoding
One method of compression is known as Run-Length-Encoding. Run-Length-Encoding searches the file for repeating patterns in text and replaces
them with a singular replacement digit which would represent that pattern. This process will result in files becoming smaller as, instead of
using the original characters from the text, it would use the single replacement digit which would reduce the overall amount of characters used.
The quote below is from the series ‘Little Britain’ and was shown to us by our Teacher. It is a good example of Run-Length-Encoding as it
contains a lot of repetition.  Some words in the quote have been colour-coded to highlight the patterns
in the text. In its original state, this quote contains 32 words and 116 characters in all (including spaces). From seeing the patterns in the quote,
we can start to compress the file in size. Let’s make it so that ‘Yeh’=1, ‘but’=2, ‘no’=3, ‘nuthin’ =4, ‘… (Ellipsis)’=5 and ‘on’=6. Now we can replace
the original patterns with the new digits as you can see below.
Some words in the quote have been colour-coded to highlight the patterns
in the text. In its original state, this quote contains 32 words and 116 characters in all (including spaces). From seeing the patterns in the quote,
we can start to compress the file in size. Let’s make it so that ‘Yeh’=1, ‘but’=2, ‘no’=3, ‘nuthin’ =4, ‘… (Ellipsis)’=5 and ‘on’=6. Now we can replace
the original patterns with the new digits as you can see below.
 We can now see that the original patterns have been made redundant and have been replaced by the singular
digit that represents it. Some words remain in their original forms as there were no repeating patterns in them to replace. The quote has been compressed from
116 characters down to 72. This shows that, through RLE, this quote has seen reduced to 62% of its original size. This method is a way that computers can use
to compress pictures as each colour would be represented by binary which would have the patterns contained within it. The compression program being used can
then use these patterns to shorten the amount of data needed to represent the colour. The same principle would apply for notes in a music video.
We can now see that the original patterns have been made redundant and have been replaced by the singular
digit that represents it. Some words remain in their original forms as there were no repeating patterns in them to replace. The quote has been compressed from
116 characters down to 72. This shows that, through RLE, this quote has seen reduced to 62% of its original size. This method is a way that computers can use
to compress pictures as each colour would be represented by binary which would have the patterns contained within it. The compression program being used can
then use these patterns to shorten the amount of data needed to represent the colour. The same principle would apply for notes in a music video.
When referring to compression… two terms are often used: Lossy compression and Lossless compression. ‘Lossy’ means that, when the file is reconstructed, there will be pieces missing which will result in poorer quality. Lossless means that, when the file is reconstructed, it will return to its exact original state. Run-Length-Encoding is a lossless way of compressing data as it can be returns to its exact previous state when the file is reconstructed.
This is an experiment we did in class on zipping files:

File A:

File B:

Another example of compression is when a file is zipped (compressed) using applications such as WinZip or WinRAR. With these methods, the more repeating patterns there are in a file or the more a pattern is repeated, the better the compression will be as it will mean that more sets of characters will be replaced by singular digits. We can see this because, as we can see, File A has compressed further than File B because of the constant repeating pattern of ‘Computer Science is great’. Because this File A has 1 pattern repeated over and over instead of jumbled text like File B, it allows it to be compressed further as more of the code can be represented by replacement digit. So when it comes to compression, it is important to know that, the more repetition, the better.
Error Control
Error Control is a computer’s way of ensuring that data is correct before it is used for its objective. Error control is very important in current society as it assists us with such things as VIAS number entries as well as our everyday activities from reading a CD to ensuring that data on a Hard Drive is correct. Errors in everyday data can have various causes whether it be a damage barcode on a product, interference in the transmission of data or simply by data being input incorrectly. You could go into a store and try buying a bag of crisps and end up paying for cologne because of an incorrect barcode. One method a computer system detects data errors is through a process known as Parity.
There are two types of parity; odd parity and even parity. The idea of parity is that the computer records the amounts of 1s and 0s in a line of code. If the data is recorded using even parity (an even amount of 1s in the line of code) and comes out at the other end with an odd number of 1s, the computer will detect that the data has been changed and will correct it. This would also work if something with an odd amount of 1s was sent and it was received with an even amount of them.
This parity interactive can be found at: http://csfieldguide.org.nz/en/interactives/parity/index.html
 The example on the left is showing how parity works. The idea is that, in the first screenshot (A), you fill the last row and
column with a black or white tile so the amounts of black and white tiles are even. The first row has 6 white bits and 4 black bits. Everything in that row is even. This is
not the case with the second row so it must be fixed. This continues until all of the rows have even bits in them. Once this is accomplished, the result was the second
screenshot a finished chart where I completed the data set. I completed it so that each row and column had an even number of black and white tiles in them e.g.
0, 2,4,6,8 tiles of either colour. This would mean that the data would be using even parity. In the second screenshot (B), one of the tiles has been flipped and,
using parity checking, I had to establish which one was flipped. In the end, I realised that the flipped tile was the one in the lower left corner as the column
it was in and the row it was in, both have an odd number of black and white tiles in them. This told me the exact placement of the altered tile and allowed me
to change it (resulting in screenshot C). The flipped tile in the screenshot B is meant to represent changed or faulty data which could be acquired through
transmission or could be changed by a faulty hard drive while data is being stored. Parity is a very useful system as it uses a simple and logical process to
determine missing or faulty data. This will help correct the data as it could save someone losing a lot of money in a bank or help stop vital information from
being mistaken and carried out incorrectly.
The example on the left is showing how parity works. The idea is that, in the first screenshot (A), you fill the last row and
column with a black or white tile so the amounts of black and white tiles are even. The first row has 6 white bits and 4 black bits. Everything in that row is even. This is
not the case with the second row so it must be fixed. This continues until all of the rows have even bits in them. Once this is accomplished, the result was the second
screenshot a finished chart where I completed the data set. I completed it so that each row and column had an even number of black and white tiles in them e.g.
0, 2,4,6,8 tiles of either colour. This would mean that the data would be using even parity. In the second screenshot (B), one of the tiles has been flipped and,
using parity checking, I had to establish which one was flipped. In the end, I realised that the flipped tile was the one in the lower left corner as the column
it was in and the row it was in, both have an odd number of black and white tiles in them. This told me the exact placement of the altered tile and allowed me
to change it (resulting in screenshot C). The flipped tile in the screenshot B is meant to represent changed or faulty data which could be acquired through
transmission or could be changed by a faulty hard drive while data is being stored. Parity is a very useful system as it uses a simple and logical process to
determine missing or faulty data. This will help correct the data as it could save someone losing a lot of money in a bank or help stop vital information from
being mistaken and carried out incorrectly.
Bar Code Verification/ISBN numbers
One real life situation where error cannot be afforded is when reading the number on a bar code. Bar codes must be read correctly at check-outs in shops in
order to ensure that customers are charged for the correct item or that a system error does not occur. The way this is done is by using a check digit at the
end of a bar code. An algorithm is used to calculate the check digit .First, take the number, then multiplying  every 2nd digit by 3.
After this takes place, add all the resultant numbers and all the other numbers (1st, 3rd, 5th, etc.) together to end with a finishing number. The check digit is the
difference between this number and the next multiple of 10. In class, we created a spreadsheet to show the process of the check digit calculation. As you can see,
every 2nd digit was multiplied by 3 to give larger numbers while the other numbers remained the same. The numbers were added to make 121. This made the check digit 9
as it was the difference between 121 and 130.
every 2nd digit by 3.
After this takes place, add all the resultant numbers and all the other numbers (1st, 3rd, 5th, etc.) together to end with a finishing number. The check digit is the
difference between this number and the next multiple of 10. In class, we created a spreadsheet to show the process of the check digit calculation. As you can see,
every 2nd digit was multiplied by 3 to give larger numbers while the other numbers remained the same. The numbers were added to make 121. This made the check digit 9
as it was the difference between 121 and 130.
Encryption
Encryption in vital in our everyday lives for reasons of security and privacy. These files can range from secret military documents to simple bank statements.
The reason of encryption is to keep specific information from falling into the wrong hands.
`Encryption is a method of mixing up data so that it cannot be read. The whole point of it is to prevent something’s true meaning being discovered or just make
it harder to read. There are many different methods of encrypting data. Some include the Caesar Cipher, the mobile phone Cipher and Morse Code.
A Cipher is basically a term for an encryption.
The Caesar Cipher
The basis of the Caesar Cipher is the idea of representing a specific letter by using a different letter of the alphabet. Every Cipher (method of encrypting) must have a key. Say the message you are given is “WTAAD IWTGT BPITN”. Because this message makes no sense it can assumed that it has been encrypted. If we can find out the key, then we can translate the code. In this case Cipher is 15 meaning that the letters we are shown are 15 letters further up the alphabet than the actual letter.
 Knowing this key, we can work out the code. Let’s start with the letter ‘W’. Because the key is 15, we move 15 spaces back down
the alphabet… which lands us at ‘H’. So, the first letter is ‘H’. Then the second letter; because the letter is ‘T’ is 15 letters along the alphabet from the letter ‘E’, the
second letter is ‘E’. We can keep repeating this technique until we find the entire code. The code now reads “HELLO THERE MATEY”.
Knowing this key, we can work out the code. Let’s start with the letter ‘W’. Because the key is 15, we move 15 spaces back down
the alphabet… which lands us at ‘H’. So, the first letter is ‘H’. Then the second letter; because the letter is ‘T’ is 15 letters along the alphabet from the letter ‘E’, the
second letter is ‘E’. We can keep repeating this technique until we find the entire code. The code now reads “HELLO THERE MATEY”.
The image to the left shows my classmates and I conducting experiments using the Caesar Cipher.
Morse Code
Morse Code is another method of encryption that uses a series of dots and dashed to represent characters and letters. Every letter has a different sequence of dots and dashes that are used to represent them. For example:
'S' in Morse Code is three dots and 'O' is three dashes.
This means that 'SOS' (Save Our Souls) would come out in Morse Code as '... --- ...'
Public Key/Private Key
When sending documents across the internet it could be very easy for someone, with malicious intent, to access them if they are not properly protected. The way that messages used to be encrypted across the internet was that the person sending the message would encrypt the message and then send the password or encryption key to the recipient. The recipient could easily decode or decrypt the message… but so could a hacker who intercepts the message. This method of encryption is known as Symmetric Encryption. The answer to this problem of interception is the idea of Asymmetric Encryption.
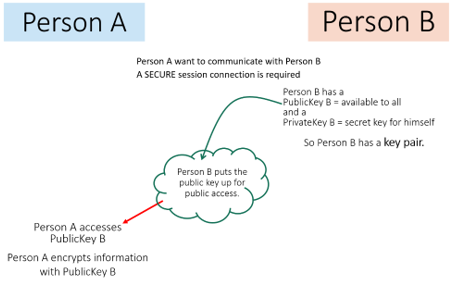
Asymmetric Encryption is a far more secure way of encrypting data for transport across the internet. If one person ,’Person A’, wanted to send a confidential file to another person,’B’, the Asymmetric Encryption method would mean that Person B would create a pair of encryption keys, the Public Key and the Private Key. As the names suggest, the Public Key would be released onto the internet publically and Person B would keep the Private Key confidential. Person A would retrieve the Public key from the net and then encypt the information using it. Because the Public key and Private key are a pair, the Public key can only be decrypted by the Private key which is kept safe by Person B. Person A would then send the encrypted information to Person B who can then decrypt the message using the Private key and read it. This can all be seen in the diagram to the left. It is important to note that Person A, because the Public key can only be decrypted by the Private key, Person A cannot alter the encrypted information after it has been encrypted. If he/she makes a mistake, then they cannot go into the file to alter it. The way around this problem is to create a copy of the file before encrypting it with the Public key and then you will always have a backup file to alter and then re-encrypt. This is why it is important to keep a back-up file of all documents you create.
Hashing
 Another method of encryption is seen when creating a password to be used on the internet. The password needs to be kept securely so that anyone with malicious
intent cannot access your information. This would be very important for banking websites or sites that store personal information One way to add security to an online password is through the process known
as hashing.If the hashing algorithm is good then the properties of the hash should be that, when you hash the same password, it will give the same hash and that the hash should be near impossible to decrypt
from it’s hashed state back to the original password. Mathematically, hashing is a one-way process. This means that it is very easy to create a hash of any given password but it is very difficult to decrypt
to find the original. For example: If I used the password “DarkWolf”, this password would be hashed into a specific code. When I tried this, the result of the hash was the following code:
Another method of encryption is seen when creating a password to be used on the internet. The password needs to be kept securely so that anyone with malicious
intent cannot access your information. This would be very important for banking websites or sites that store personal information One way to add security to an online password is through the process known
as hashing.If the hashing algorithm is good then the properties of the hash should be that, when you hash the same password, it will give the same hash and that the hash should be near impossible to decrypt
from it’s hashed state back to the original password. Mathematically, hashing is a one-way process. This means that it is very easy to create a hash of any given password but it is very difficult to decrypt
to find the original. For example: If I used the password “DarkWolf”, this password would be hashed into a specific code. When I tried this, the result of the hash was the following code:
36360c5800861db8a55c8524babf6c4f
I found this by using the MD5 hash generator at: http://www.md5hashgenerator.com/